Exercise 3 - A Zoo of Models
Exercises | | Links:
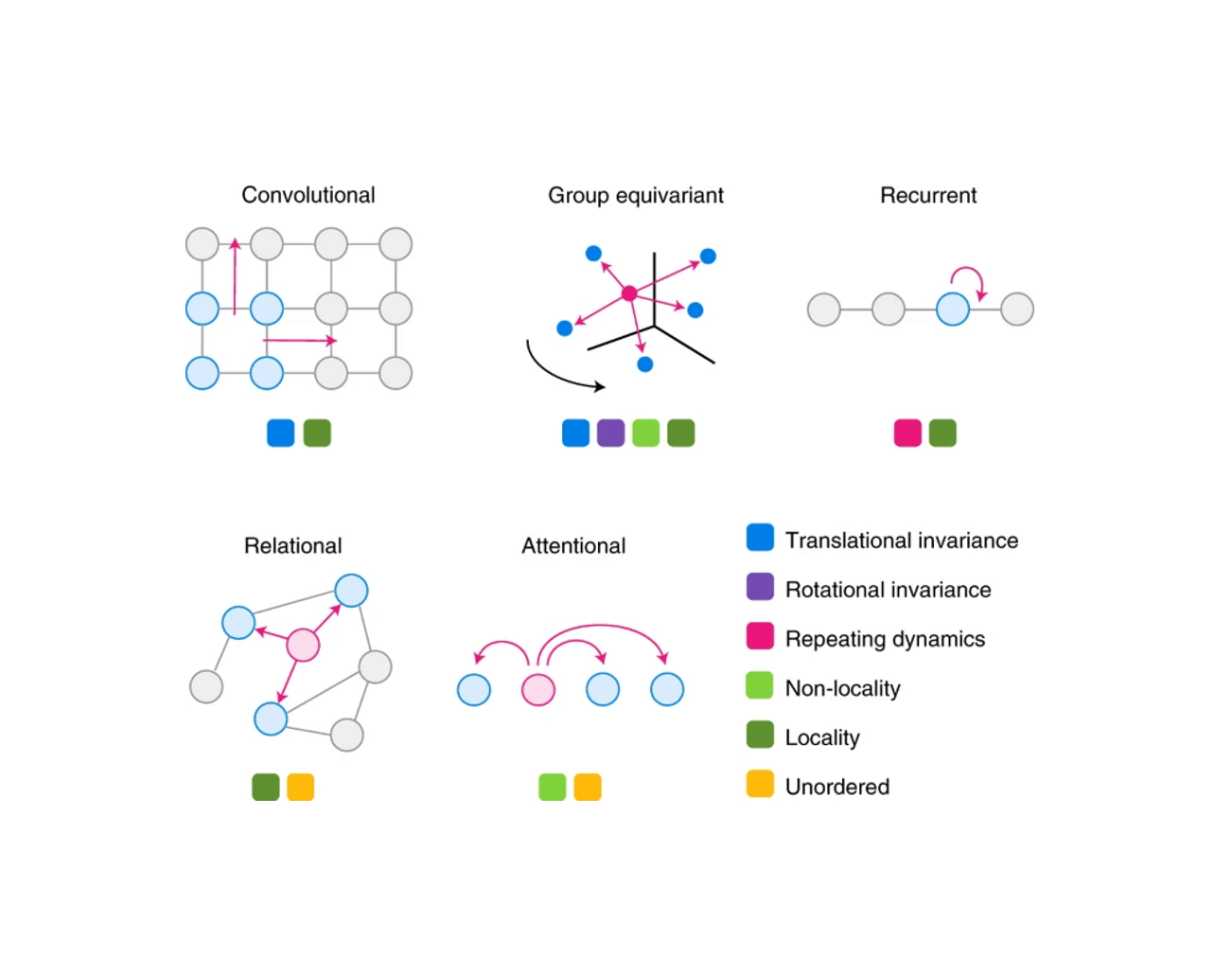
In this exercise your understanding of the different model classes presented in the lecture is testeds
In this week’s exercises, we try to both understand how to use different network architecture to instill different inductive biases into our networks and how to use visualisation techniques to understand more about the inner workings of the networks that we train.
Exercise 3.1 - Coding Convolutional Neural Networks
Follow the following tutorial to train an image classifier via a CNN. This tutorial is part of a tutorial series about PyTorch; if there are commands or concepts that you do not understand, you can always go back to the previous tutorials on that webpage to get a better understanding.
Try to understand the different components of the network and how they work together to classify the images. Try to change the network architecture and see how it affects the performance of the network. How do different kind of poolings/different kernel sizes affect the performance? Can you explain why?
Can you get similar performance via a simple MLP? Why/why not? What is the tradeoff?
Exercise 3.2 - Understanding CNNs
In this exercise, we will try to understand how CNNs work by visualising the filters that they learn. To do this, read this blog post. Try to confirm their findings by looking at the visualisation results in the OpenAI Microscope yourself. Are there any other interesting examples you find/examples that confirm or falsify the claims of the authors?
Exercise 3.3 - Coding word embeddings and Transformers
To understand word embeddings, implement and follow this tutorial.
For Transformers I gave you a multitude of resources in the lecture; for this exercise, I want you to follow along this tutorial and implement the code he links on GitHub in your Colab notebook. Remember that you can get a free GPU on Colab by going to Runtime -> Change runtime type -> Hardware accelerator -> GPU.
Exercise 3.4 - Understanding word embeddings and Transformers
Try to get an intuition for word embeddings by playing with them on this webpage. Why are there certain words that are close to each other? Is it due to correlation or causation? Can you find any interesting examples? For example, what happens if you add the word pair doctor - nurse to the Gender analogies embedding? Do you see a problem there?
To understand transformers a bit better, read through this blog post answering some of the most common questions people have. Another great post to read through is this one, which explains some of the problems with Transformers and evaluations of these models in general. What does the author mean by the “Clever Hans moment in NLP”? What would be things you could look out for to prevent something like this happening?
If you are adventorous, you can look at the Transformer Circuit Thread that tries to explain transformers in a more visual way, inspired by the original Circuit thread we looked at when interpreting CNNs. It is a bit more advanced, but if you are interested in the topic, it is a great resource!
Credits
The title image of this exercise is from an excellent review paper by Mohammed AlQuraishi & Peter K. Sorger called Differentiable Biology; a highly recommended read!